Instructing and Prompting Large Language Models for Explainable Cross-domain Recommendations
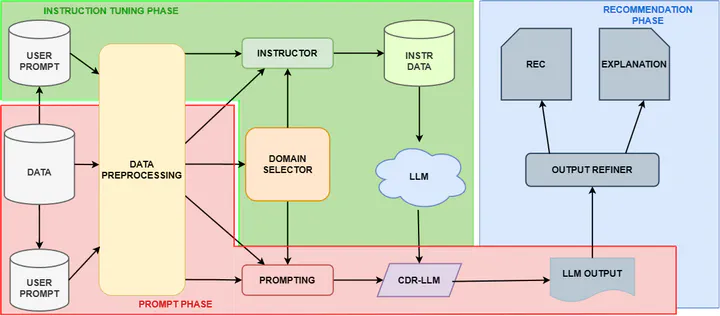
This sutdy explores how to improve cross-domain recommendation systems using large language models (LLMs). Cross-domain recommendation systems (CDRs) help users receive personalized recommendations across different areas, such as suggesting books based on a user’s movie preferences. However, these systems often suffer from data sparsity, making it difficult to gather enough labeled data from both domains (source and target) to train the models effectively.
To address this, we propose a strategy that uses the knowledge encoded in LLMs to bridge the gap between different domains. The key innovation is to prompt LLMs by providing user preferences from one domain (e.g., movie ratings) and applying that knowledge to recommend items in another domain (e.g., books). The paper outlines a workflow that involves fine-tuning the LLM through instruction-based learning and carefully designed prompts that generate recommendations along with natural language explanations.
The experimental results show that this approach outperforms other state-of-the-art models, both in zero-shot (no prior domain-specific training) and one-shot settings (limited training), making it a promising direction for more explainable AI-driven recommendation systems.